Do you know what a Kubernetes architecture diagram is? What about kubectl, microservices, serverless computing, Kubernetes monitoring, AWS, containers, Fluentd, pods, nodes, or scaling? You’ve likely heard these essential computing terms, but do you fully grasp how they work together?
Even if you’re familiar with these concepts, do you genuinely understand their practical applications? If you do, keep reading. You’re about to deepen your knowledge. If not, sit back and let me break it down for you.
We’re about to deconstruct Kubernetes from the ground up, exploring Kubernetes architecture diagrams, real-world examples, core components, and practical use cases. By the end, you’ll understand what Kubernetes is and how to use it effectively. Get ready for a deep dive into scalability, orchestration, and containerized deployments like never before.
A Kubernetes cluster architecture refers to the structure of a system that includes a primary control plane and one or more worker nodes. Alternatively, it could be even more if you utilize Kubernetes self-managed services like kubeadmn, kops, etc.
Both instances can be in the cloud, virtual machines, or even physical devices. However, when it comes to managed Kubernetes architecture diagram environments like Azure AKS, GCP GKE, and AWS EKS, the control plane is managed by the designated cloud provider.
When large-scale enterprises wish to perform mission-critical tasks, they’ll use Kubernetes, an open-source system for container management and a perfect solution for their needs.
Besides its basic framework capabilities, Kubernetes is helpful on other fronts. It allows users to choose from various options, such as languages, logging and monitoring tools, and types of application frameworks, along with numerous other valuable tools they may require.
Kubernetes is not a Platform as a Service (PaaS) per se, but you can use it as a complete PaaS starting base.
Since its introduction, Kubernetes has become a popular tool and one of today’s most successful open-source platforms.
Hire our Kubernetes consulting services for robust, scalable Kubernetes architectures
We need Kubernetes simply because it allows us to distribute our workloads efficiently across all available resources and optimize infrastructure costs.
All applications deployed within Kubernetes are known as microservices, and they are composed of numerous containers further grouped into series as pods. From here, every container is logically designed to perform a singular task.
Read the full blog on the benefits of microservices.
Almost all container orchestration engines can deliver application availability. However, Kubernetes’ high availability architecture exists to achieve the availability of both infrastructure and applications. It also ensures high availability on the application front by utilizing replication controllers, pet sets, and replica sets.
Kubernetes (High Availability) also supports infrastructure availability, including a wide range of storage backends. These include block storage devices like Amazon Elastic Block Store (EBS), Google Compute Engine persistent disk, etc.
Kubernetes’ design offers various choices in operating systems, container runtimes, cloud platforms, PaaS, and processor architectures. In addition, you can configure a Kubernetes cluster on different Linux distributions like CentOs, Debian, Fedora, CoreOS, Ubuntu, and Red Hat Linux.
You can deploy it in a local or virtual environment based on KVM, libvirt, and vSphere.
The Serverless architecture for Kubernetes can run on cloud platforms like Google Cloud, Azure, and AWS. Still, you can also create a hybrid cloud if you mix and match clusters across cloud providers or on-premises.
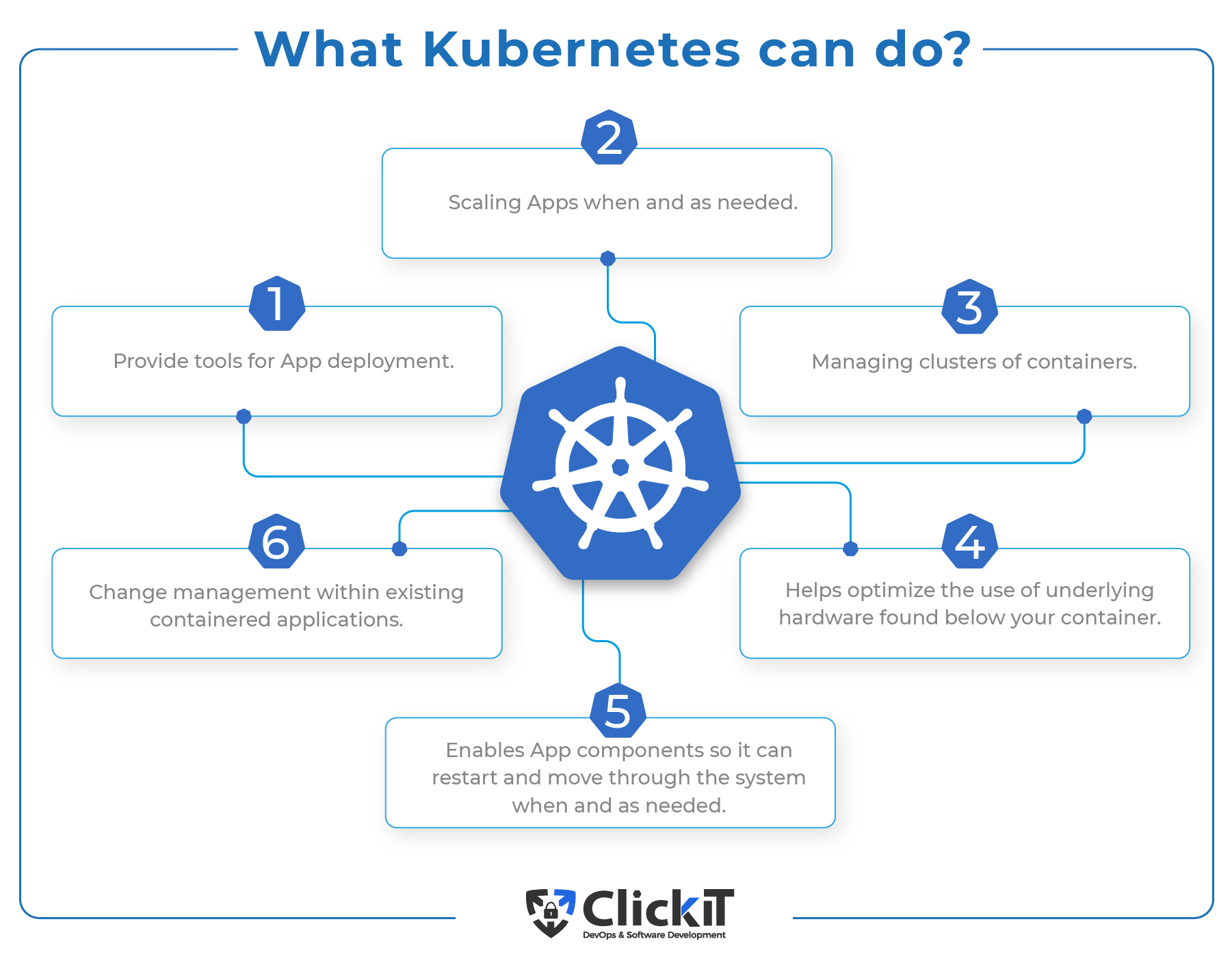
Kubernetes will automatically package your application and create container scheduling based on all available resources and requirements without sacrificing availability. As a result, Kubernetes will balance between best effort and critical workloads to save unused resources and ensure complete utilization.
Kubernetes provides peace of mind regarding networking and communication since it automatically assigns IP addresses to containers. In addition, for a set of containers, it gives a single DNS name that will load-balance traffic within the cluster.
Kubernetes architecture diagram allows you to choose the system storage you want to mount. You can opt for public cloud providers like AWS, GCP, or even local storage. Moreover, you can use shared networks storage systems like iSCSI, NFS, etc.
Kubernetes is capable of automatically restarting all containers that fail during execution. In addition, it will kill all containers that don’t respond to health checks previously defined by the user. Finally, if the node dies, it will reschedule and replace all failed containers in all other available node.s
Kubernetes can assist you with updating and deploying secrets and application configuration without rebuilding your image and exposing the secrets within the stack configuration.
Besides managing services, Kubernetes can handle your batch and CI workloads, which will replace failed containers if need be
Kubernetes requires a single command to scale up the containers, but it can also scale them down with CLI. You can perform scaling via the Dashboard found in Kubernetes UI.
Kubernetes can progressively roll out updates and changes to your app or its configuration. If something goes wrong, Kubernetes can and will roll back the change.
These were some of the most critical advantages of the Kubernetes architecture diagram, but that’s not all Kubernetes offers. Therefore, let’s explore the more attractive aspects of Kubernetes and its practical use cases.
It became a huge deal when enterprises implemented the Kubernetes architecture diagram in their data centers over the alternative (public cloud providers). It’s only natural that these several essential factors were crucial for companies to decide on Kubernetes on-premises strategy implementation:
Every business has specific business policy requirements, like the need to run workloads accurately in specified geographical locations. Considering the specific policy needs, you’ll understand why it might be difficult for a business to utilize public clouds.
In addition, some companies may not accept offers from various public cloud providers if the mentioned business has strict business policies regarding their competition.
Numerous enterprises want to avoid using services from one cloud provider because they may want to deploy their apps across multiple clouds, including an on-premises (private) cloud. As a result, businesses will reduce the risk of perpetual impacts due to specific cloud providers’ issues.
Moreover, this allows companies to negotiate much better prices with cloud providers.
At scale, running your apps in public clouds can be costly, and cost-efficiency is probably the most important reason for using Kubernetes on-premises.
In addition, if your apps rely on processing and ingesting large amounts of data, you can expect to pay top dollar to run them in the public cloud environment.
On the other hand, utilizing “in-house” Kubernetes will significantly reduce operational costs thanks to the existing data center.
Some organizations have specified regulations regarding data privacy and compliance issues. For example, these rules may prevent companies from serving their customers in different world regions if their services are nested in specific public clouds.
If you opt out of Kubernetes on-premises, you will effectively modernize your apps into a cloud-native format with your own data centers. This will significantly transform your business. An effective strategy like this will help you save a lot of money while undoubtedly improving the use of infrastructure.
You can download our slideshow Why do enterprises and companies adopt Kubernetes?
Yes, companies that want to work with Kubernetes architecture use containers on a huge scale as they don’t use one or two containers. Still, dozens and even 100’s to ensure high availability and load balance the traffic.
As traffic surges, scaling up containers becomes essential to handle the growing number of requests per second. Conversely, scaling down optimizes resource usage during low demand and reduces costs.
But here’s the challenge: manual container management is tedious, time-consuming, and inefficient. This raises an important question is all this manual effort worth it? The answer lies in automation.
This is where container orchestration tools come in, and Kubernetes leads the market. With its powerful auto-scaling capabilities, Kubernetes dynamically adjusts container numbers based on real-time traffic demands, saving hours of manual labor.
Its dominance isn’t just about features Google created Kubernetes, making it one of the most trusted, scalable, and widely adopted container management solutions today.
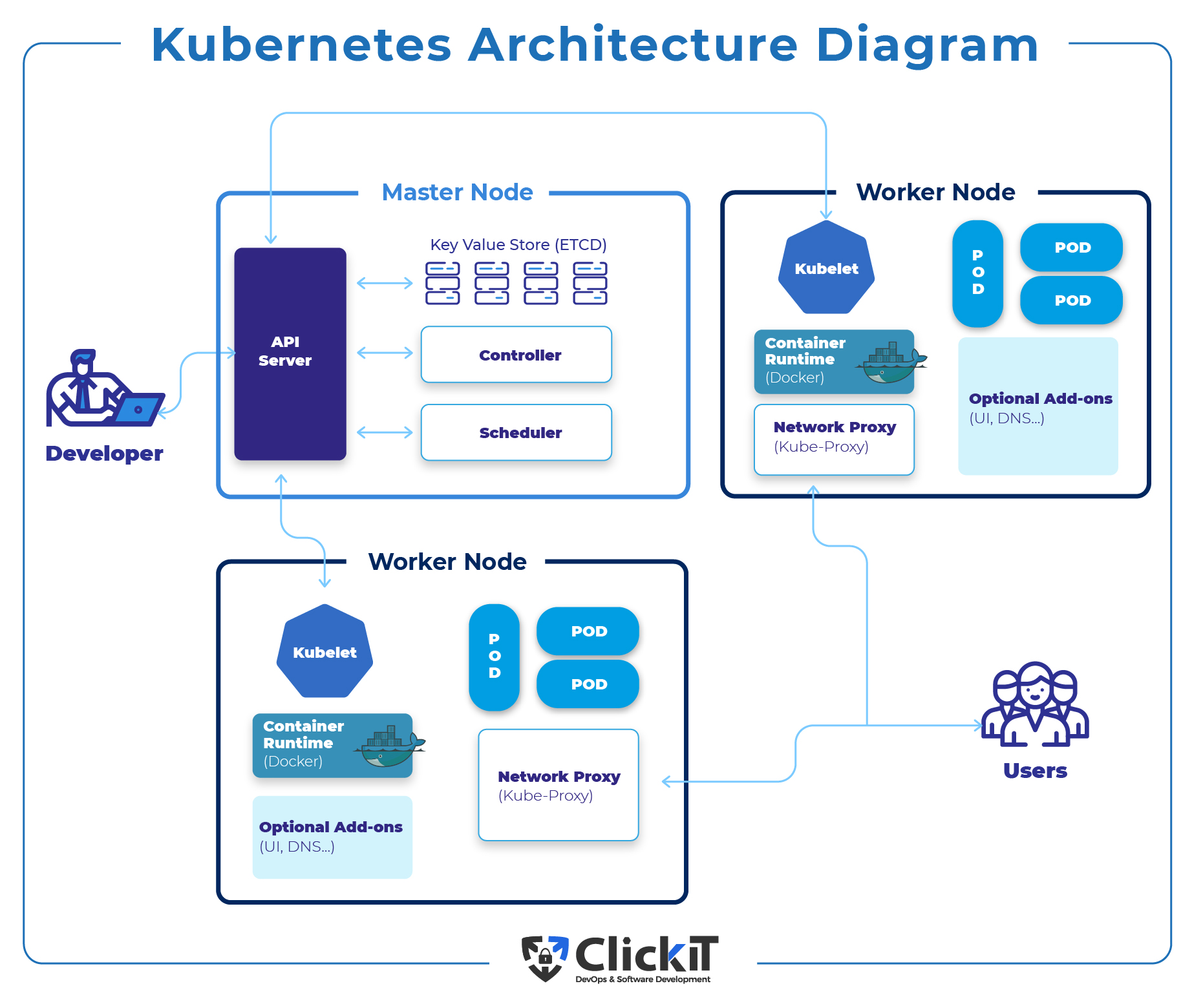
Components of the Kubernetes architecture diagram are nodes (set of machines) and the control plane. Now, let’s get deeper into those components.
Master Node is the starting point for all administrative tasks, and its responsibility is managing the Kubernetes architecture diagram.
It’s possible to have more than one master node within the cluster, and what’s required for checking the fault tolerance as more master nodes will place the system in the mode known as “High Availability.”
However, one master node is the primary node that performs all the tasks.
Pod is a single application controlled by one or several containers. A pod contains a unique network ID, application containers, and storage resources to determine how it’ll run containers.
Pods can easily suffer a change. Therefore, Kubernetes can’t assure that a physical pod will remain alive (if the replication controller ends and begins with new pods).
Instead, the service will display a logical set of pods and act as a gateway. This means that you won’t have to keep track of the pods that make up the service, as pods can send requests to it.
is a virtual cluster that works in environments with multiple users across numerous projects. It’s worth mentioning that one physical cluster can run several virtual clusters simultaneously.
Resources within a namespace have to be unique, and they won’t be granted access to another namespace. Moreover, it’s possible to allocate a resource quota to a namespace so you can avoid overconsumption of overall resources found in the physical cluster.
In Kubernetes, the volume will apply to a whole pod. Therefore, it’ll mount on all containers located in the specified pod. Even if the container restarts, Kubernetes can guarantee that all the data will be saved. However, if the pod is killed, the volume will also disappear. A pod can have numerous volumes of different types.
Deployment depicts the pod’s desired state or replica set, usually in a yaml file. The controller will slowly update the environment until the current and expected state match, as specified in the deployment file. This environment update includes deleting or creating replicas.
The yaml file defines two replicas for each pod. However, when only one is running, the yaml file definition will also create another one. Therefore, it’s essential to know that they shouldn’t be directly manipulated when deployment manages replicas. Use new implementations instead.
When talking about a high level, the Kubernetes architecture diagram consists of several segments like the control plane (master node), several Kubelets (cluster nodes), and ETCD (distributed storage system that helps keep a consistent cluster state).
The control plane is a specific system that perpetually manages object states, helps match the actual and desired state of system objects, and responds to any changes within the cluster.
The control plane consists of three essential components: kube–scheduler, Episerver, and kube-controller-manager. These components run on a single master node and can even replicate across several master nodes (high availability).
Even though every controller is an isolated process, you can merge multiple controllers into a single binary, but it will run as a single process for complexity reduction purposes.
These are some controller types:
Worker Node runs apps via Pods, and Master Node controls the Pods. Pods are scheduled on a physical server (slave node). So, you must connect to these nodes when you want to access the apps from an external environment.
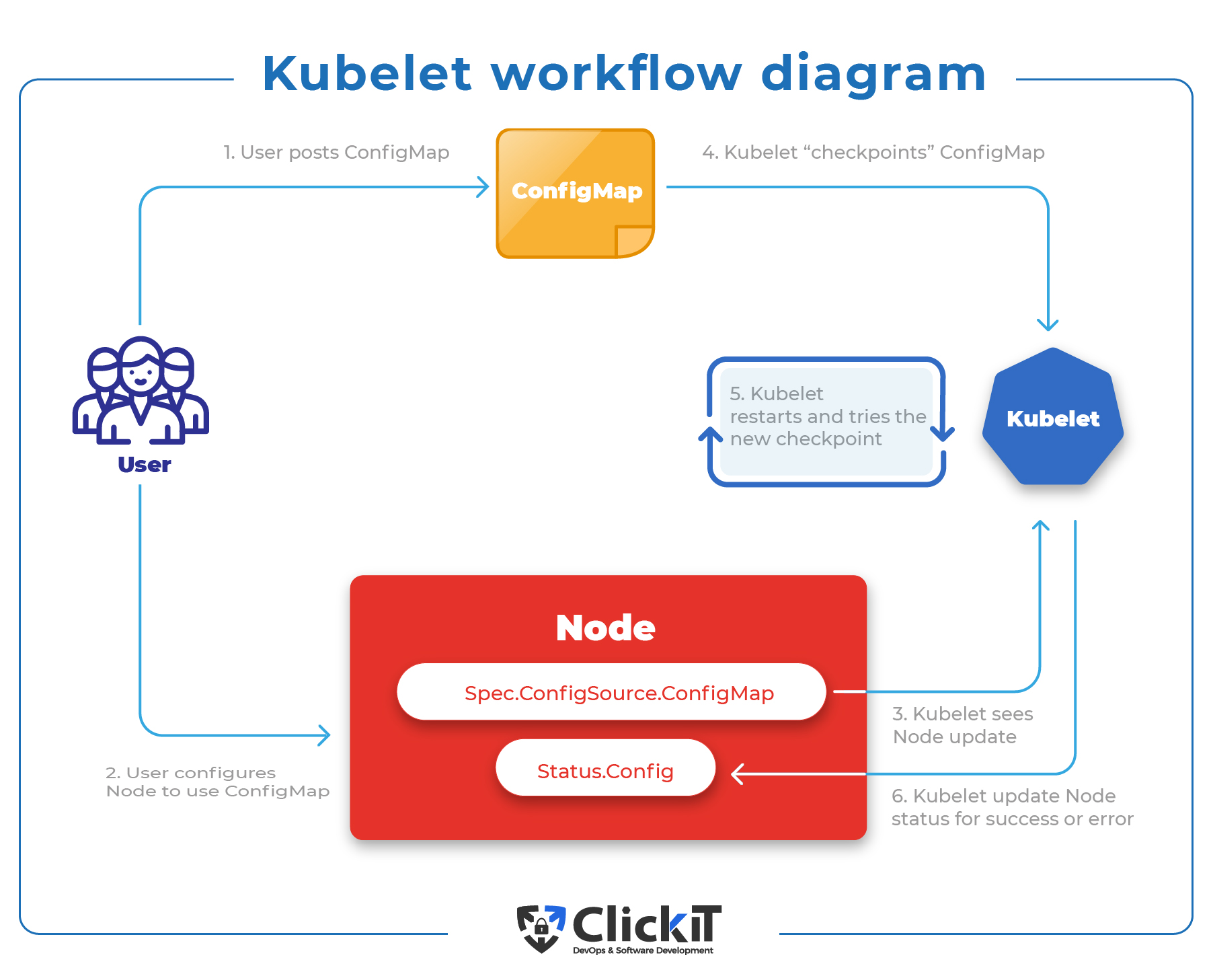
A more practical solution is to present you with an illustrated diagram of Kubelet workflow so you can better understand how it works. Below is a detailed but quick presentation of Kubelet workflow.
It’s always fun to explore the depths of a Kubernetes architecture diagram, and ETCD is a crucial element of a great example. Kubernetes stores all cluster state information in ETCD, which is known as the sole stateful element of the control plane.
ETCD is highly consistent, allowing it to be the anchor coordination point. In addition, thanks to the Raft consensus algorithm, ETCD is highly available.
Another excellent feature of ETCD is that it can stream changes to clients. This helps all Kubernetes cluster components to be in sync.
This is a command-line tool for Kubernetes, and it helps you run commands. In addition, Kubectl is beneficial for managing and inspecting cluster resources, viewing logs, and application deployment.
Kubectl gives users the ability to control access to perform any Kubernetes operation. From a more technical standpoint, kubectl is Kubernetes API’s client.
The “IP-per-pod” model is how Kubernetes operates. This means that every pod is assigned with an IP address. Moreover, containers in a single pod will share the same IP address and network namespaces.
Usually, the CNI will use an overlay network to conceal the pod’s underlying network by utilizing VXLAN (traffic encapsulation). Moreover, it can utilize other solutions that are fully routed. Whichever solution it uses, a cluster-wide pod network is where pods will communicate, and CNI providers manage this communication.
There are no restrictions within a pod, so containers can communicate between themselves because when in a pod, containers share the same IP address and network namespace. Meaning containers’ communication is done via localhost. Secondly, communication between pods is possible thanks to the pod IP address.
Kubernetes is based on the volume concept; in essence, a volume is a directory that possibly contains some data that a pod can access. However, the use of a specific volume type determines its content, selects the medium that backs up this directory, and explains how this directory came to be in the first place.
Any container in a pod can consume storage in the same pod. Storage will initially survive when pods restart, but what will happen after the pod has been deleted depends on the storage type.
Various available options allow you to mount block and file storage to a pod. The most popular ones are cloud storage services like gcePersistentDisk and AWS EBS. Alternatively, physical storage like iSCSI, Flocker, NFS, CephFS, and glusterFS are options.
In the end, StorageClasses are an abstract layer that allows you to see the quality difference of underlying storage. Furthermore, operators use StorageClasses to depict different storage types, which provides storage with dynamic provisioning based on all incoming claims from every pod.
Supervisors primarily manage and create processes. However, the starting point of these processes is the data within the configuration file. If you wonder how a supervisor does this, the answer is simple—it creates subprocesses.
Supervisord will manage every subprocess it creates as long as the subprocess is alive. That’s why supervisord is referred to as a parental process for its “offspring” of subprocesses.
Fluentd is a trendy open-source data collector that you can set up on your Kubernetes nodes. You’ll quickly transform and filter the log data and follow up on container log files upon setting it up. By doing so, you can deliver them to the Elasticsearch cluster for indexing and storing the data.
Deployment provides Kubernetes with instructions for modifying or creating pod instances that carry a containerized app. Deployments can achieve numerous goals, like enabling the rollout of updated code within a controlled environment, scaling the replica pod numbers, and rolling back the code to the previous deployment version in case you need to roll it back.
The most meaningful benefit of Kubernetes deployment is the automation system for various repetitive functions (scaling, updating in-production applications, deploying).
Additionally, the automatic pod instances launching mechanism provides peace of mind since now you can rest assured your instances will run as intended and across all nodes within the cluster. In essence, the more automation you have, the better. You’ll also experience fewer errors even though your deployments are much faster. OpenShift enables automation inside and outside your Kubernetes clusters; here’s a complete comparison between OpenShift vs Kubernetes.
Thanks to ongoing health and performance monitoring of nodes and pods, Kubernetes deployment can bypass downed nodes or even replace a failed pod. The deployment controller can easily replace pods to ensure seamless work for all vital applications.
The Kubernetes architecture diagram is not easy to understand initially, but your life and time at work will become much more manageable when you do.
We’ve learned that Kubernetes is an excellent solution for scaling, supporting diverse and decoupled stateful and stateless workloads, and providing automated rollbacks and rollouts. It’s also a fantastic platform for orchestrating your applications (container-based).
Today, we went through a lot of information together. I hope that you now have a much better understanding of Kubernetes, what it is, and how it works. If you want to know anything we haven’t discussed yet, contact us, and a professional from our team will help you with any questions.
This blog is also available on DZone. Don’t forget to follow us there
A Kubernetes cluster is a defined set of nodes that run containerized applications. Compared to virtual machines, clusters within the Kubernetes cluster architecture are more flexible and lightweight, providing easy management, movement, and application development.
Kubernetes constructs are essential as they breathe life into your containerized application. When it comes to construct, a great Kubernetes architecture example is deployment, as this construct is in control of pod destruction and creation.
The main differences between Docker and Kubernetes include that Kubernetes runs across a cluster while Docker runs on one node. Another essential difference is that you can use Docker without Kubernetes, but for Kubernetes architecture to work, you need a container runtime to orchestrate.
Kubernetes control plane is the brain of the Kubernetes architecture diagram. The control plane makes all the decisions and communicates with the data plane (the body) through kubelet.
Kubernetes architecture is built around two main parts: the Control Plane and Worker Nodes.
The Control Plane manages the cluster’s overall state and includes key components like the API Server, which handles communication, etcd, which stores all configuration data; the Scheduler, which assigns pods to nodes, and the Controller Manager, which ensures the cluster remains in its desired state.
Worker Nodes are where applications run, with components like the Kubelet to manage containers, Kube-Proxy to handle networking, and the Container Runtime (e.g., Docker) to run the containers. Together, these elements ensure Kubernetes can efficiently manage and scale containerized applications.
Kubernetes handles networking by assigning each pod a unique IP address, allowing direct communication between pods, even across nodes.
It uses services to provide stable access points for groups of pods, including ClusterIP, NodePort, and LoadBalancer.
Kubernetes also includes an internal DNS service, enabling pods to find services using DNS names instead of IP addresses, ensuring seamless communication and load balancing.
Advanced prompt engineering strategies are important when extracting maximum value from Large Language Models (LLMs).…
Today, I will discuss which one is better, Python vs Node.js for AI development, so…
At this point, if AI isn’t part of your application, you’re falling behind in a…
As a CEO, I know that attending the top AI conferences 2025 is an excellent…
Why is Python frequently regarded as the top programming language for developing Artificial Intelligence? Based…
AWS launched a data center in Mexico. This new region, based in Querétaro with three…
{kind=link}
{kind=link}
{kind=link}
{kind=link}