
In today’s busy world, where information is important, handling data well is crucial for success. Regarding managing data, there are two significant choices: Amazon Redshift vs Snowflake or Snowflake vs Redshift are useful tools each with its special features.
Snowflake is a fully self-managed service that simplifies data management. No virtual or physical hardware needs to be installed, configured, or chosen by the user. Remarkably easy to set up, the software requires little installation or configuration.
On the other hand, Amazon Redshift, designed by Amazon Web Services (AWS), is a fully managed cloud data warehouse solution that can store petabytes of data. You may access and analyze data using Amazon Redshift Serverless without worrying about setting up a deployed data warehouse. In order to provide quick performance for even the most demanding and unpredictable workloads, data warehouse capacity is intelligently scaled and resources are dynamically allocated.
Now, let’s take a closer look at Snowflake vs Redshift, kind of like looking at different tools in a kitchen. Consider Amazon Redshift vs Snowflake as special data-handling tools. To make it easier for you to select the data management tool that best fits your needs, let’s open the drawer and see how these, Snowflake vs Redshift, tools function.
Table of contents
- What is Snowflake?
- Benefits of Snowflake
- What is Amazon Redshift
- Benefits of Amazon Redshift
- Snowflake vs Redshift: Comparison
- Summary
- Amazon Redshift vs Snowflake: When should you use it?
- Conclusion
- Amazon Redshift vs Snowflake FAQs
What is Snowflake?
In the context of evaluating Amazon Redshift vs Snowflake, let’s delve into what Snowflake is and what it brings to the table.
Snowflake’s Data Cloud is a fully self-managed service that runs on a cutting-edge data platform. Compared to conventional systems, this platform enables faster, more easily accessible, and incredibly flexible data processing, storage, and analytics options.
Snowflake relies solely on cloud infrastructure, using storage services for persistent data storage and virtual compute instances for computation requirements. It’s crucial to remember that Snowflake can only be used on public cloud infrastructures; it cannot be hosted or run on on-premises private cloud systems.
As a true self-managed service, Snowflake stands out in its hands-off approach to hardware and software management. Users are relieved from the responsibilities of selecting, installing, configuring, or managing any hardware, whether virtual or physical.
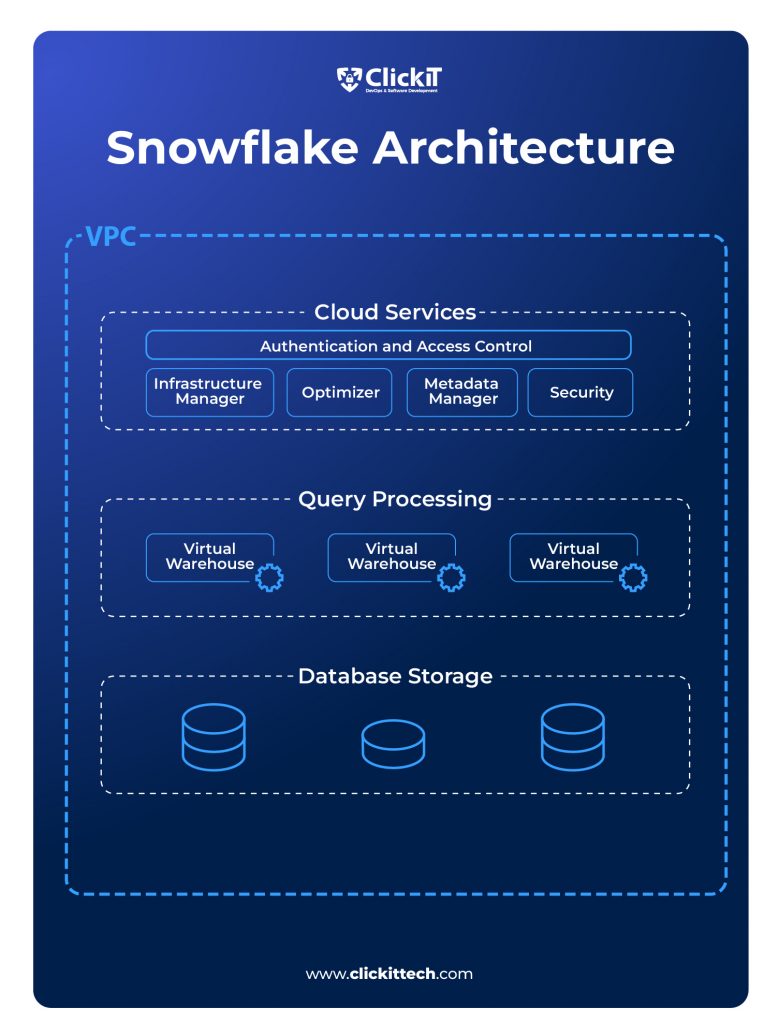
Snowflake’s unique architecture comprises three essential layers:
- Database Storage
The Snowflake platform reorganizes data upon ingesting it into a compressed, columnar, internally optimized format. Next, cloud storage is used to store this enhanced data. Snowflake manages organization, file size, structure, compression, metadata, statistics, and other components of the data. Interestingly, clients can only retrieve this data by running SQL queries through Snowflake. - Query Processing
Queries are executed in the processing layer, where Snowflake makes use of “virtual warehouses.” These virtual warehouses, which are made up of numerous compute nodes that Snowflake has assigned from a cloud provider, function as Massive Parallel Processing (MPP) compute clusters. Every virtual warehouse functions autonomously, ensuring that its operations do not affect the efficiency of other virtual warehouses. The query processing efficiency is improved by this configuration.
Virtual warehouses from Snowflake come in two varieties: Standard and Snowpark-optimized. In order to carry out different tasks within a Snowflake session, these virtual warehouses play a role in providing the required resources, including CPU, memory, and temporary storage. The following are the primary functions that a virtual warehouse supports:- Executing SQL SELECT Statements:
- Performing DML Operations:
- Cloud Services
A group of services that coordinate operations within Snowflake make up the cloud services layer. These services connect all of Snowflake’s various parts to handle user requests, from login to query dispatch. Among the services this layer manages are:- Authentication
- Infrastructure management
- Metadata management
- Query parsing and optimization
- Access control
Benefits of Snowflake
Within the space of cloud-based data warehousing solutions, Snowflake stands out as a strong and adaptable platform with an array of benefits catered to business needs. The following are the key benefits that set Snowflake apart in the constantly changing field of data management and analytics. Let’s explore these advantages to compare Amazon Redshift vs Snowflake.
- Multi-Cloud Deployment Capability:
Hosting options available on all three of the major cloud computing platforms-Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure-Snowflake offers unmatched flexibility. Your Snowflake account can be deployed in one or more regions supported by each of these platforms. Snowflake lets you align your Snowflake accounts on the same platform for easy integration, regardless of whether your company currently uses AWS, GCP, or Azure for its cloud services. - Automatic encryption:
Data is automatically encrypted in Snowflake both while it’s in transit and at rest. Snowflake employs best-in-class encryption, which drastically reduces the amount of data protected by a single key by encrypting each partition in each table using a different key in a hierarchical approach. Additionally, automatically every 30 days, snowflake-managed keys are rotated.
- Granular access controls:
By offering role-based access control on table objects, which immediately translates to privileges on underlying micro-partitions, Snowflake makes managing privileges to your data easier. No matter which underlying cloud provider Snowflake is placed on, table owners can provide privileges to end users using commands that work with the exact same syntax. The grants are replicated automatically and maintained in sync with the Snowflake service, even if your tables are replicated across clouds. - Cross-cloud replication:
If you choose to save in cloud storage, you are frequently limited to the cloud’s and the region’s availability. No more reliance on a single cloud or region—Snowflake’s cross-cloud features seamlessly replicate, redirect users, and enable smooth transitions. This implies that you can promote secondary replica account objects in another region or cloud platform to act as read-write primary objects in the event of an outage in the first region or cloud platform. Additionally, Snowflake allows you to seamlessly migrate your account to a new cloud platform or location, which is helpful in the event of mergers, acquisitions, or adjustments to your cloud strategy. - Automatic versioning, Time Travel, and Fail-Safe:
Because of automated Time Travel and Fail-Safe features, you don’t have to worry about data accidentally being deleted or updated when stored in Snowflake. Time travel allows you to view the status of items and data in the past and, if needed, UNDROP objects. - Pay-for-usage model:
Snowflake simplifies pricing with a consumption-based model, ensuring you pay solely for the resources utilized. This model provides the flexibility to scale your usage according to demand, granting you control and clear visibility into both usage and expenditure.
| Sr. No. | Benefits | Summary |
| 1 | Multi-Cloud Deployment Capability | Host on AWS, GCP, or Azure. Flexible deployment in various regions. Seamless integration across platforms. |
| 2 | Automatic encryption | Automated encryption for in-transit and at-rest data. Robust encryption practices with key rotation. |
| 3 | Granular access controls | Role-based access controls for simplified data access management. Consistent syntax across cloud providers. |
| 4 | Cross-cloud replication | Eliminate reliance on a single cloud. Seamless replication and transition across clouds. |
| 5 | Automatic versioning, Time Travel, and Fail-Safe | Time Travel and Fail-Safe prevent accidental data loss. View past states and recover objects. |
| 6 | Pay-for-usage model | Pay only for utilized resources. Flexible scaling for control and clear expenditure visibility. |
What is Amazon Redshift
Now, let’s see what Amazon Redshift brings to the table while we are discussing Amazon Redshift vs Snowflake
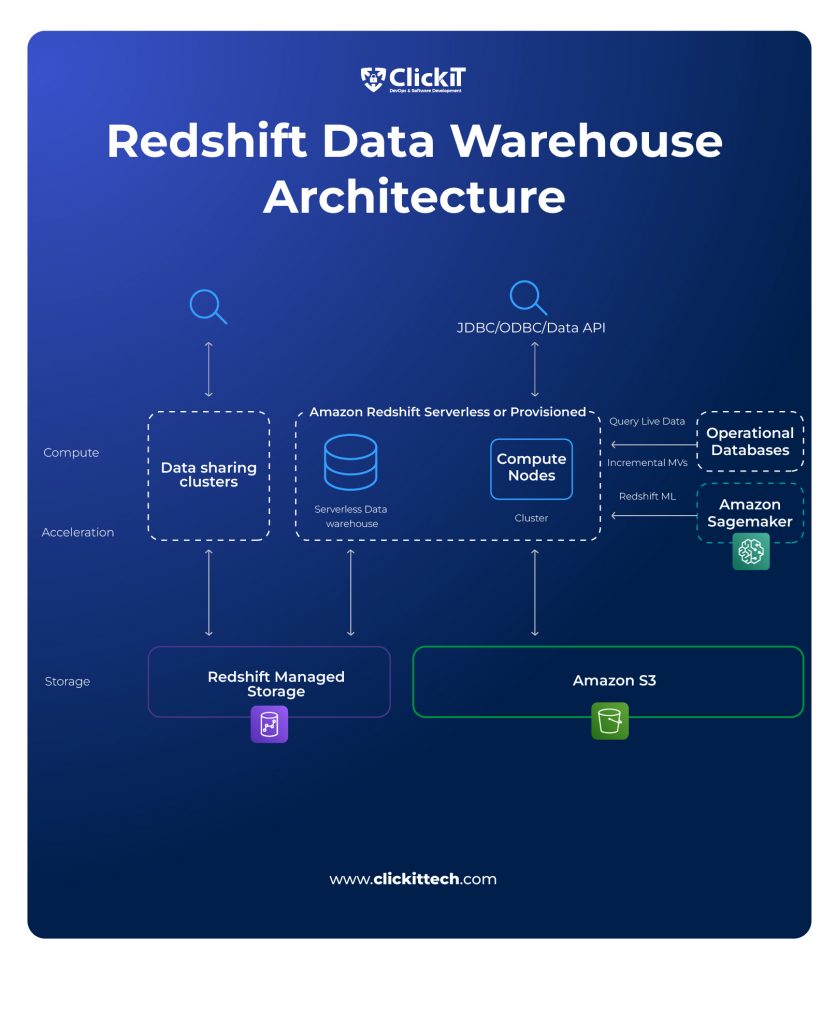
AWS offers a cloud-based data warehouse service called Amazon Redshift, which is fully managed. Redshift is a popular cloud computing platform that is cost-effective, scalable, and ideal for high-performance analysis and reporting. The entire process of setting up, managing, and scaling a data warehouse is handled by the Amazon Redshift service. These responsibilities include allocating capacity, keeping an eye on the cluster, backing it up, and updating the Amazon Redshift engine with fixes.
Amazon Redshift cluster is made up of one or more compute nodes and a leader node. Your needs for query runtime performance, the number of queries you want to execute, and the amount of your data will all determine what kind and number of compute nodes you require.
As your demands for data warehousing grow, you can quickly scale up to a bigger, multi-node cluster from a small, single-node cluster. Importantly, the cluster’s functionality remains unaffected when computing nodes are added or removed, ensuring seamless scalability and performance optimization.
To accommodate various scenarios, Amazon Redshift offers two unique usage options:
- Amazon Redshift Provisioned Cluster:
This mode works well with workloads that are constant and predictable. - Amazon Redshift Serverless:
When anticipating compute requirements becomes difficult, the serverless solution is the best alternative.
Benefits of Amazon Redshift
As a cloud-based data warehousing solution, Amazon Redshift provides a number of advantages that meet the various needs of enterprises. The following are the main benefits of utilizing Amazon Redshift, let’s explore them to understand Amazon Redshift vs Snowflake better.
- AWS Services Integration:
You can move, transform, and load your data fast and reliably with Amazon Redshift’s integrations with other AWS services, all while utilizing data security safeguards. - Moving data between Amazon Redshift and Amazon S3
Amazon Redshift reads and loads data from numerous files stored in Amazon S3 buckets quickly and effectively by using parallel processing. Additionally, you can export data to many data files on Amazon S3 using parallel processing from your Amazon Redshift data warehouse. - Using Amazon Redshift with Amazon DynamoDB
Data from a single Amazon DynamoDB database can be loaded into an Amazon Redshift table using the COPY command.
- Importing data from remote hosts over SSH
Data from one or more remote hosts, such as Amazon EMR clusters, Amazon EC2 instances, or other Computers, can be loaded into Amazon Redshift using the COPY command. Through SSH connections, commands are executed on these remote hosts to generate data. - Automating data loads using AWS Data Pipeline
Automating the transfer and transformation of data into and out of Amazon Redshift is made possible by AWS Data Pipeline. By utilizing its integrated scheduling features, customers can automate repetitive tasks without requiring intricate data transfer or transformation algorithms. - Migrating data using AWS Database Migration Service (AWS DMS)
Data movement to and from Amazon Redshift is made easier by AWS Database Migration Service (AWS DMS). Numerous databases, including Oracle, PostgreSQL, Microsoft SQL Server, Amazon Aurora, DynamoDB, and more, can be migrated to and from with this service.
- Concurrency Scaling:
With consistently high query performance, customers may easily manage a large number of concurrent users and queries with Amazon Redshift’s Concurrency Scaling functionality. This dynamic capability becomes especially important in environments where the demand for concurrent processing power varies.
Concurrency Scaling ensures that queries are processed quickly and without apparent delays by automatically adding query processing power in a matter of seconds as demand for concurrency increases. What establishes concurrency adapting to different workloads is what makes it scale apart. The additional processing capacity is released immediately and wisely whenever the workload needs to decrease. - Serverless:
With Redshift’s serverless solution, users may leverage data warehousing capabilities without requiring manual cluster provisioning. This mode offers a cost-effective option for scenarios with changing workloads, periodic workloads with idle time, or steady-state workloads with demand spikes since resources scale automatically based on the actual query workload. - Security & Governance:
Standard-compliant industry-grade security measures are offered by Amazon Redshift. With its smooth integration with AWS IAM Identity Centre, it provides strong security features, including multi-factor authentication, granular access limits, and single sign-on. Amazon Redshift uses encryption to protect your data while it is in transit and at rest. Notably, there are no additional fees for any of these security elements, meaning that even the strictest security, privacy, and compliance regulations can be satisfied without adding to the financial load. - Price Performance:
For a variety of analytical workloads, Amazon Redshift provides the best price/performance ratio. With up to 6x better price performance than competing cloud data warehouses and up to 7x better price performance for high concurrency, low latency applications, Amazon Redshift is a self-learning, self-tuning system. With the help of concurrency scaling, massively parallel processing (MPP) architecture, machine learning-led performance optimization approaches, and the division of storage and compute, you can maintain consistently high performance for your data workloads. With pay-as-you-go, on-demand, and reserved instance price options, you can select what best suits your company’s needs.
- Redshift Reliability:
Cloud-based data warehousing solution Amazon Redshift offers recovery features to save downtime and handle unplanned disruptions. Moving a cluster to a different Availability Zone (AZ) without affecting applications is possible with Amazon Redshift. It also offers automated backups and failure remediation. Highly accessible Amazon S3 provides support for data stored in Redshift Managed Storage (RMS). To operate in several AZs at once and enable quick recovery without data loss, Amazon Redshift provides Multi-AZ setup. - Data Sharing:
Data may be shared between organisations, AWS regions, and even third-party suppliers with Amazon Redshift data sharing—all without the need for manual data movement or copying. AWS accounts, AWS Regions, Availability Zones, serverless workgroups, and provisioned clusters can all share data.
| Sr. No | Benefit | Summary |
| 1 | AWS Services Integration | Seamlessly move, transform, and load data across AWS services, ensuring swift and secure operations. |
| 2 | Concurrency Scaling | Easily handle large user volumes and queries, dynamically scaling processing power for consistently high performance. |
| 3 | Serverless | Utilize data warehousing without manual provisioning, allowing resources to auto-scale for cost-effective adaptability. |
| 4 | Security & Governance: | Meet security standards using AWS IAM, featuring multi-factor authentication and encryption at no extra cost. |
| 5 | Price Performance | Attain optimal ratios with up to 6x better performance, backed by scaling, MPP architecture, and machine learning. |
| 6 | Redshift Reliability | Minimize downtime with recovery features, automated backups, and Multi-AZ setup for data reliability. |
| 7 | Data Sharing | Effortlessly share data within and beyond organizations, AWS regions, and third-party providers, eliminating manual data tasks. |
Read our to discover the top AWS Services list
Snowflake vs Redshift: Comparison
It is crucial to understand the subtle differences between Amazon Redshift vs Snowflake, two major participants in the cloud-based data warehousing space, when comparing them. Although, Amazon Redshift vs Snowflake, both of them address the constantly increasing need for effective data management, there are notable differences between their designs, cost structures, and maintenance strategies.
Snowflake vs Redshift: Cloud Infrastructure
Snowflake
With its cloud-agnostic approach, Snowflake enables users to set up their data warehouses across AWS, Azure, and GCP. For businesses adopting a multi-cloud strategy or with varying cloud needs, this multi-cloud capabilities is beneficial. Unmatched flexibility is provided by Snowflake’s design, which facilitates seamless data exchange and redundancy across many cloud providers.
Amazon Redshift
Redshift is tightly integrated with AWS as it is an Amazon Web Services (AWS) offering. Although this integration provides wide connectivity with AWS services, it reduces flexibility for companies that are considering or currently using other cloud providers. Redshift is a great option for businesses that significantly rely on AWS services because of its architecture, which is tailored for the AWS ecosystem.
Snowflake vs Redshift: Architecture
Snowflake
The architecture of Snowflake is a unique combination of conventional shared-disk and shared-nothing database architectures, offering an extremely effective and scalable data management solution. The system makes use of a central data repository, similar to shared-disk systems, that is available to all compute nodes for persistent data. On the other hand, query processing leverages Massively Parallel Processing (MPP) compute clusters. The speed and scale-out benefits of the shared-nothing architecture are reflected in this configuration, where each cluster node keeps a localized subset of the full dataset.
Amazon Redshift
Clusters are the core building block of the infrastructure used in Amazon Redshift architecture. An extra leader node handles client interactions and coordinates external communication in these clusters made up of one or more computing nodes. Completing execution plans, delivering compiled code to the compute nodes, and processing SQL statements are all critical tasks performed by the leader nodes. The ability to scale the cluster according to workload requirements is made possible by the dedicated CPU and memory on each compute node. Redshift Managed Storage (RMS) is a separate tier that uses Amazon S3 storage to scale to petabytes for data storage.
Snowflake vs Redshift: Pricing
Snowflake
The overall cost of utilizing Snowflake is the sum of the costs associated with using compute, storage, and data transfer resources. With Snowflake, businesses pay for the actual use of its resources through a consumption-based pricing model. Users can scale resources up or down in response to demand with this flexible and cost-effective methodology. Because Snowflake only charges for what it uses, its pricing approach might be especially beneficial for businesses with varying workloads.
Amazon Redshift
Redshift has a provisioned pricing model in which customers pay for the resources that are allotted to them. During times of decreasing demand, this set pricing strategy may lead to underutilization and increased expenditures. The price structure of Redshift is better suited for businesses with steady, predictable workloads.
Read our blog How AWS Pricing Works
Snowflake vs Redshift: Maintenance
Snowflake
For effective scalability, cost optimization, and reduced downtime, wave goodbye to the headaches of manual management and welcome to smooth automation. By providing simple data management, strong security, strong governance, high availability, and resilient data practices, Snowflake’s completely managed platform transforms data operations. You can concentrate on utilizing your data instead of being sidetracked by tedious maintenance tasks with an automated strategy, which lowers risks and improves operational efficiency.
With Snowflake, users can avoid the hassles of managing hardware and software and benefit from a truly self-managed service that transforms data warehousing. With Snowflake handling all ongoing maintenance, management, upgrades, and tuning, users are freed from the burden of choosing, installing, or configuring hardware.
As part of its weekly release schedule, Snowflake gives users access to the newest features without any interruptions to their service.
Amazon Redshift
Being a fully managed service, Amazon Redshift enables AWS to efficiently manage infrastructure maintenance duties. Nonetheless, it may be necessary to make expenditures in additional tools or skilled employees in order to optimize Redshift clusters for effective query performance. These factors could raise the overall maintenance costs related to maintaining the best possible performance and functionality of the platform.
Snowflake vs Redshift: Performance
Snowflake
The processing power for running queries in Snowflake’s architecture comes from virtual warehouses, and making the most of these resources can improve query performance. Optimizing the computational resources in a warehouse is crucial for effective query processing.
Three storage strategies are available with Snowflake: Automatic Clustering, Search Optimization Service and Materialized Views.
Automatic clustering enhances query efficiency by splitting up a table’s data into smaller groups and clustering it according to certain dimensions. The arrangement of micro-partitions around particular dimensions or columns can be tailored by users by defining a cluster key. For queries that filter, join, or aggregate data according to the designated cluster key, this intentional clustering greatly increases efficiency.
For structured and semi-structured data, Snowflake’s Search Optimisation Service improves the efficiency of selected point lookup searches. Constructing a customized data structure lowers query latency.
By pre-calculating data sets, Materialised Views—which are intended for frequently asked query patterns—improve query efficiency. This is especially useful for workloads that return few rows and/or columns in comparison to the base database.

Amazon Redshift
With its Massively Parallel Processing (MPP) architecture, columnar data storage, data compression methods, advanced query optimizer, result caching, and code compilation for effective execution, Amazon Redshift achieves great performance. On the other hand, a number of variables can affect query performance.
A balance between performance and costs is required since the amount of nodes, processors, or slices affects concurrency and cost. The effectiveness of query processing and scan speed are influenced by node types, data distribution, sort order, and dataset size.
Performance considerations are further affected by the impact of code compilation, concurrent processes, and query structure optimization. Although code compilation has advantages, variables such as concurrent query complexity and version upgrades can affect results, highlighting the importance of carefully taking these aspects into account for the best possible use of Amazon Redshift.
Summary
| Snowflake | Parameter | Redshift |
| Available on AWS, GCP, and Azure | Multi-Cloud Deployment | Tightly integrated with AWS |
| Unique combination of shared-disk and shared-nothing | Architecture | Cluster-based architecture with leader and compute nodes |
| Default settings for in-transit and at-rest encryption | Automatic Encryption | Encryption must be enabled manually |
| Role-based access control for easy data management | Access Controls | Integration with AWS IAM for security and access |
| Time Travel for historical data views | Automatic Versioning & Time Travel | Automated backups, failure remediation in Redshift |
| Consumption-based pricing model | Pay-for-Usage Model | Provisioned pricing model with set resources |
| Does not directly support AWS service integration | AWS Services Integration | Primarily tailored for AWS ecosystem, with direct integration with AWS services like S3, DynamoDB, Data Pipeline, DMS |
| Strong security measures with granular access control, and default encryption. | Security & Governance | Industry-grade security with IAM, multi-factor authentication, and encryption |
| Fully managed platform, automated maintenance | Maintenance | Fully managed service, additional tools may be required for optimization |
| High performance with virtual warehouses and three storage strategies: Automatic Clustering, Search Optimization Service, and Materialized Views | Performance | Achieves great performance with MPP architecture, columnar data storage, data compression, advanced query optimizer, result caching, and code compilation |
Amazon Redshift vs Snowflake: When should you use it?
Snowflake
If your organization doesn’t use AWS often, Snowflake is a fantastic choice. It’s like having a superpower for safely transferring data between various locations, such as regions and cloud platforms, which makes collaboration a breeze. Furthermore, it’s quite easy to manage and requires very little work to maintain proper operation.
Snowflake is like a ninja when it comes to upgrades, it makes them without creating any disruptions, allowing you to continue working uninterrupted. Thus, Snowflake is your go-to hero if you value ease of use, straightforward updates, and hassle-free data sharing!
Amazon Redshift
If you have a deep integration with the AWS environment, Amazon Redshift is the best option. It provides a unified environment for your cloud-based data warehousing requirements with its smooth connectivity with a range of AWS services.
Amazon Redshift is the best choice if you’re looking for a solution that’s tightly integrated with Amazon S3, DynamoDB, and other AWS products. Its design and performance enhancements make it especially suitable for demanding reporting and analytics jobs in the AWS environment, guaranteeing peak efficiency for your data workloads.
Read our blog about the AWS Security Tools
Conclusion
In conclusion, an organization’s specific requirements, priorities, and current infrastructure will determine which of Snowflake vs Redshift is best. Amazon Redshift vs. Snowflake has its own set of benefits. Therefore, the choice should be based on factors like pricing structures, scalability needs, cloud preferences, and the desired amount of human management.
Snowflake is a great option for enterprises looking for flexibility, user-friendliness, and seamless collaboration across several cloud providers because of its cloud-agnostic approach, multi-cloud deployment capability, and automated functionality. The platform’s distinctive architecture makes it strong for innovative and dynamic businesses, especially when paired with features like cross-cloud replication, flexible access controls, and automated encryption.
On the other hand, Amazon Redshift, which is closely linked with AWS, performs best in settings where AWS services are the cornerstone. For companies with a strong presence in the AWS ecosystem, its dependability, connection with AWS services, and pricing structure designed for steady workloads make it a competitive option. Enterprises that depend on AWS services can meet their different demands with the platform’s advanced capabilities, which include serverless solutions, concurrent scaling, and powerful security measures.
In the end, the choice of Snowflake vs Redshift comes down to a thorough evaluation of organizational requirements. Although Amazon Redshift’s close integration with AWS services offers a specialized solution for companies with a strong foothold in the AWS environment, Snowflake’s flexibility and hands-off approach make it a useful tool for a variety of scenarios.
Amazon Redshift vs Snowflake FAQs
Yes, Snowflake supports multi-cloud deployment, allowing users to choose between Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
Indeed, AWS is the only platform on which Amazon Redshift is compatible. It is an AWS cloud-based data warehouse service that makes use of AWS resources and infrastructure. If you’re searching for a data warehousing solution outside of the AWS ecosystem, you could be better off looking at alternatives like Snowflake, which allows deployment across many clouds.
Yes, Snowflake enhances data security by automatically encrypting data while it’s in transit and at rest.
With Amazon Redshift Serverless, you can take advantage of data warehousing capabilities without manually provisioning clusters. It offers a financially viable solution for fluctuating workloads by automatically scaling resources according to the real query workload.





